Stack (堆疊, 棧)#
在開始說明執行中的程式在記憶體當中長什麼樣之前,首先必須先了解什麼是Stack (堆疊)。
在資料結構中,Stack (堆疊)是基本且重要的結構之一,且日常生活中處處可見,例如撲克牌、彈夾、漢堡(?)
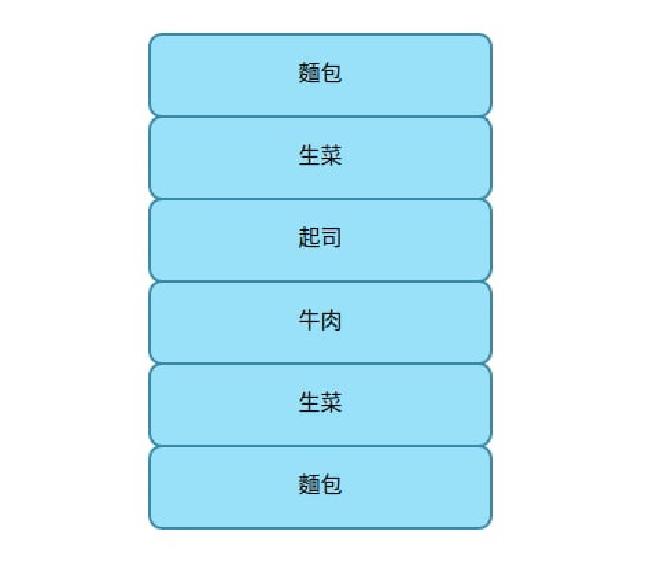
可以看到漢堡的各個部份被堆疊起來,而堆疊結構有個特性 — 「先進後出,FILO (First In, Last Out)」。
試想製作漢堡的過程是在桌面上,放上最底層的麵包,接著疊上生菜、牛肉。
當要將材料拿下來時,則必須是先拿起最上方的牛肉,接著拿下生菜,最後才是第一個放上的麵包。
(P.s. 堆疊一次只更動一個項目,也就是說在上述例子中,不能將生菜跟牛肉一起拿起來)
在堆疊最上方添加物件稱作「Push」,而拿取 Stack 最上方物件的動作則稱作「Pop」。
基本上這就是堆疊,很好理解對吧!在Pwn的過程會時常見到它 :)
Queue (佇列, 堆)#
提到Stack就不得不跟著提到Queue (佇列)。
與堆疊不同的是,Queue有著「先進先出,FIFO (First In, First Out)」的特性。
在生活中的例子有摩天輪、排隊等。

假設排隊點餐的情境下有一隊伍如上圖:
排在首位的是王小明,也稱為「Head」,也就是佇列的「頭」;
而排在最末端的是「新之助」,也稱作「Tail」,為佇列的「尾」。
其FIFO特性為,當排隊點餐時,先排的人有先點餐的優先權。
若要添加新的物件,則從後方添加。
(摩天輪亦是如此,先坐上的人,會先轉完一圈回到地面。)
Segments and Sections#
字面上來說,「Segment」表示「段」,而「Section」則是翻譯成「節」,是差不多的意思…
這兩個詞在現今的計算機領域中已被混淆使用著,許多場合人們並不會在意這兩個詞的區別。
後續的內文將其統稱「區段」、「段」,並在必要時用英文區分。
可以想像,在寫程式時所建立的Functions、Variables、Constants… 都需要被存放在執行檔中,而不同類型的資料被存放在不同的區域用以區分,這些區域就稱作「Sections」。
「Segment」則可以理解成是這些Sections的劃分群組,舉例常看到的兩個用於存放資料的Sections,分別叫做「.data」與「.bss」(做什麼的等等再解釋),這兩個Sections所在的Segment就被稱作Data Segment (資料段)。
而一個Segment可以包含0 個或多個Section。另外,通常Section的名字前方都會有個英文句號「.」作為前綴。
各個Segments都有著不同的用途,以下將說明最基礎的兩個Segments的作用:
Text Segment (文字區段)#
又稱作
Code Segment (程式區段),用以存放程式碼與唯讀資料的區段。
通常包含著像是.text、.rodata、.plt、.plt.got、.dynsym等Sections。.text (.code)#
又被寫作「
.code」,如其名為存放程式碼的區段。(此指的程式碼為Machine-Language Instructions (機器碼指令集),畢竟已經是執行檔了,所以存放的是二進制程式碼)(P.s. 目前較主流的指令集架構為Intel x86,沒聽過沒關係,暫時先留個眼就好)
且由於該區段不需要被修改,因此通常是Read-Only (唯讀)的,也防止非預期錯誤而竄改到指令碼。(程式碼是用來執行的,因此只需要Read,你不太需要在編譯完後又修改執行檔本身).rodata#
「
ro」為「Read-Only (唯讀)」的縮寫,用於存放唯讀的資料。理論上Const (常數)會被存放於.rodata,但編譯器也可能會將部份直接寫在.text區段,至於原因可以觀看這篇文章:「c - GCC: why constant variables not placed in .rodata - Stack Overflow」。
Data Segment (資料區段)#
該區段用以存放
Global Variable (全域變數),並且是是可寫區域。
通常包含著像是.data、.bss、.got等Sections。.data#
又稱「
已初始化資料區段 (Initialized Data Segment)」,用以存放已初始化的Global Variable (全域變數)。.bss#
又稱「
未初始化資料區段 (Uninitialized Data Segment)」,「bss」為「Block Started by Symbol」之縮寫。該區段用於存放未初始化的Global Variable (全域變數),該區段的這些未被初始化的資料會在程式執行時被定義成Null(或0)。
P.s. 若變數被初始化為0、Null,則可能在編譯過程轉而被寫進.bss Section。
請注意,上述的內容並不是代表該Segment內僅僅存在這些Sections,而只是抓取幾個重要基礎作討論。
Stack, Heap#
Stack與Heap指的是記憶體上的區域,雖然也會被稱作Stack Segment與Heap Segment,但與剛才所提的Segments並不同。剛才所提的那些Segments是存放於執行檔中靜態存在的,當該執行檔執行時,檔中的Segments將會被複製到記憶體上,接著開始執行。
而Stack與Heap則是會在程式執行時才被創建在記憶體中,且隨著程式執行更動內容。
Stack#
.textSection 中會被存放各個「Function (函式)的相關資訊」及其中的Local Variable (區域變數),然後在程式運作過程中陸續被放到Stack當中(隨著程式執行到相關資料,屆時資料才會被放上Stack)。並且Stack上的資料會在各Function執行結束後,自動回收刪除該 Function 所使用的區域,因此不太需要擔心記憶體不夠使用的問題。Function (函式)的相關資訊又包含Arguments (參數)、Return Address (返回位址)等。
(P.s. 這部份之後會再提到,先大概知道是在存放什麼即可)
Stack的大小是固定的,該區段屬於Static Memory Allocation (靜態記憶體分配),也就是說在執行程式之前,儘管Stack並未被創建,但其大小是可以被計算出來的。
Heap#
寫過
C++之類語言的人可能也用過Pointer (指標),這種Reference Type Variable (引用類型變數)的值為記憶體位址,該位址存放於Stack,而該位址所對應的值則是存在Heap。另外像是在「
C++」中使用new生成的物件亦是存放在Heap,並且都會被建議當這類物件在不需要被使用時,開發者應該使用「delete」手動結束該物件的生命週期,因為Heap並不像Stack那樣有著固定的生命週期可以回收所創建的東西,因此若是程式語言沒有所謂的「Garbage Collection (GC, 垃圾回收)」機制,則可能會造成記憶體在程式執行過程中,被佔用的空間只增不減的問題,最後甚至導致記憶體不足以再供應程式使用。(而像是C#、Java、Go… 等語言皆支援GC機制)前面所提到,
Stack大小是固定的,因此可以說其所存放的資料長度是不變的,且對於Reference Type Variable也僅僅是存放記憶體地址,而存放於Heap的資料長度是要可以被更動的,因此該區段為Dynamic Memory Allocation (動態記憶體分配)。
References#
- 《C 語言程式的記憶體配置概念教學 - G. T. Wang》https://blog.gtwang.org/programming/memory-layout-of-c-program/
- 《CS 225 | Stack and Heap Memory》https://courses.engr.illinois.edu/cs225/sp2022/resources/stack-heap/